
Exploring State-of-the-Art Models for Document-Level Entity Relation Extraction

Document-level entity relation extraction involves identifying and categorizing relationships between entities mentioned within whole documents, rather than individual sentences.
Document-level entity relation extraction presents unique challenges due to complex dependencies and context beyond individual sentences. Entities may exhibit relationships across different sections of a document, making it essential to capture meaningful connections at a broader scope.
By investigating state-of-the-art generative models, we aim to enhance our understanding of entity relations within documents and unlock the potential for more comprehensive information extraction.

The dataset consists of 4883 annotated invoice-type documents written in German, where each document has been manually annotated with entity groups. We split the dataset into train, validation, and test datasets, with 3418 documents, 722 documents, and 733 documents, respectively. The dataset consists of the following features:
Document: This feature is a dictionary containing the document's ID and filename, providing essential metadata for easy identification and organization.
Tokens: Represented as a list of strings, this feature holds the tokens present in the document, allowing for a detailed analysis of the textual content.
Token IDs: Each token in the document is assigned a unique ID, enabling efficient indexing and retrieval of information.
Page IDs and Line IDs: These features are lists of integers that represent the page numbers and line numbers where the tokens appear within the document, providing spatial context to the data.
Annotated Entities: This feature is a list of dictionaries that represent the named entities identified within the document. Each dictionary contains information such as the entity's name, instances of the entity (with unique IDs and corresponding text), and the token IDs associated with each instance.
Annotated Entity Groups: This feature is a list of dictionaries that represent the entity groups found within the document. Each dictionary includes the group's name, instances of the group (with unique IDs and associated entity IDs), and the entity IDs corresponding to each group instance.
Minimal preprocessing was performed, primarily involving structuring the annotated entity groups by converting entity IDs to their corresponding words from the text.

One of the major challenges encountered during preprocessing was the constraint of fitting the entire document within the models' input, given their maximum input length of 512 tokens. Despite attempts to chunk the documents and their associated groups, it was found that approximately 94% of the documents had groups that resided within the first 512 tokens. The inclusion of empty chunks not only prolonged the training time but also introduced considerable noise to the dataset. Consequently, the decision was made to extract only the initial 512 tokens from each document, ensuring the feasibility of the task while maintaining data integrity.
Task Modeling
This study approaches relation extraction as the extraction of entity groups from a document, where each group consists of an item or concept along with associated numerical values. Unlike tasks relying on semantic associations, here, the relationships depend primarily on the text layout. This structural aspect adds complexity, demanding an effective understanding of text hierarchy to identify and extract accurate entity groups. By framing relation extraction in this context, the study aims to explore targeted approaches to address these unique challenges and enhance the accuracy of relation extraction algorithms and models.
Experiments
In this study, we conducted three experiments to explore different approaches for relation extraction (RE) in the context of document-level entity relation extraction. Each experiment aimed to investigate the effectiveness of specific methods in identifying and grouping entities based on their relationships within the document text.

NER + RE Experiment: In the first experiment, we combined Named Entity Recognition (NER) with RE. This approach simulates a realistic scenario where entities are recognized and labeled within the document text. By leveraging NER, we aimed to add complexity to the task, requiring the model to recognize entities and their relationships based on the provided textual context.
Tags + RE Experiment: The second experiment utilized specific tags to emphasize entities within the document text. This approach eliminated the need for a separate NER task, as entities were explicitly marked with tags. By doing so, we aimed to simplify the process of entity recognition and focus solely on the RE aspect of the task.
Entities + RE Experiment: In the third experiment, we explored the use of annotated entities within the document while disregarding the entire document text. The focus here was on the arrangement and grouping of identified entities to uncover underlying patterns and dependencies. By isolating the entities and their relationships, we aimed to understand the influence of entity information alone on the RE task.
Prompting
In addition to the three experiments, we utilized prompting, a technique involving specific instructions or queries to guide the language model's generation process. Prompting serves as a context for coherent and relevant responses. The model can operate in both zero-shot and one-shot settings.
In zero-shot, the model generates responses without any specific examples, relying solely on the provided instructions. In one-shot, a single example is given to guide the model's comprehension and generation.
The choice of prompt significantly influences the model's output, making it a crucial factor in our study. By incorporating prompting, we gained insights into how it affects the model's performance in document-level entity relation extraction, enhancing our understanding of its adaptability and responsiveness to different prompts.

We employed three types of prompts corresponding to each experiment:
Experiment 1 (NER + RE) Prompt: "Find all entities from the invoice-type document written in German. After finding all the words that are entities, group all entities that are related according to the document text. Don't include dates and personal information such as email addresses, IBAN, phone numbers, and addresses. Group ONLY entities that are related, not all of them. Related entities are entities that represent a row of a table and relate to the same item. Groups are usually made of one entity that resembles the item or a concept, and the rest of the group are numbers that relate to it. The output must be a list of lists, each list within the main one is a group of entities that belong together."
Experiment 2 (RE) Prompt: "Extracted entities are: "{annotated_entities}" from the invoice-type document written in German. After finding all the words that are entities, group all entities that are related according to the document text. Don't include dates and personal information such as email addresses, IBAN, phone numbers, and addresses. Group ONLY entities that are related, not all of them. Related entities are entities that represent a row of a table and relate to the same item. Groups are usually made of one entity that resembles the item or a concept, and the rest of the group are numbers that relate to it. The output must be a list of lists, each list within the main one is a group of entities that belong together."
Experiment 3 (Entities + RE) Prompt: "Extracted entities are: "{annotated_entities}" from the invoice-type document written in German. Group all entities that are related. Don't include dates and personal information such as email addresses, IBAN, phone numbers, and addresses. Group ONLY entities that are related, not all of them. Related entities are entities that represent a row of a table and relate to the same item. Groups are usually made of one entity that resembles the item or a concept, and the rest of the group are numbers that relate to it. The output must be a list of lists, each list within the main one is a group of entities that belong together."
Models
The models selected were based on their relevance and performance in natural language processing tasks. Each model is introduced, along with its architecture, strengths, and limitations, to assess its effectiveness in capturing and extracting entity relations within documents.
T5 (Text-to-Text Transfer Transformers): T5 is a transformer-based neural network architecture that has gained significant attention for its impressive performance on various language tasks. It uses a sequence-to-sequence framework for text conversion and can be fine-tuned on specific tasks. Its flexibility and efficiency make it a promising candidate for document-level entity relation extraction.
Multilingual T5: An extension of T5, multilingual T5 models can process multiple languages and generate text in any of those languages. They offer the advantage of handling multiple languages without the need for separate models, reducing computational costs for multilingual NLP systems.
FLAN-T5: FLAN-T5 builds on the original T5 architecture and underwent extensive fine-tuning on over 1,800 language tasks, resulting in enhanced reasoning capabilities and promptability. Its customizability and performance across NLP tasks make it a prominent player in the field.
GPT (Generative Pre-trained Transformers): The GPT architecture, based on the Transformer model, revolutionized language processing with its autoregressive generation capabilities. It effectively captures long-range dependencies and contextual information, making it a powerful tool for language generation tasks.
GPT-3.5 Turbo: An advancement over GPT-3, GPT-3.5 Turbo demonstrates enhanced proficiency and reduced hallucinatory responses. Its versatility and integration with the user-friendly ChatGPT platform offer practical applications in various domains.
GPT-4: The latest iteration, GPT-4, surpasses its predecessors in accuracy and performance. It excels in handling longer contexts and has an extended token span, yielding more accurate and coherent responses. OpenAI's extensive investment in human feedback enhances GPT-4's intelligence and self-control, addressing challenges related to toxicity controls.
Results
Experimental Configuration

In model performance evaluation, mT5 surpasses both T5 and FLAN-T5 across all ROUGE metrics. FLAN-T5, despite being trained on multiple languages, exhibits similar performance to T5. Interestingly, using only annotated entities without document text consistently yields the highest performance across all models. On the other hand, the inclusion of tags does not significantly improve the model's performance.
ROUGE metrics provide valuable insights into model evaluation. Specifically, ROUGE1 scores higher than ROUGE2 scores, indicating a better match in terms of individual word or entity identification and matching. Furthermore, ROUGEL scores higher than ROUGE2, emphasizing the significance of considering the overall structure and length of relations in the evaluation process. Overall, these metrics help assess the model's ability to capture and replicate text patterns and relationships effectively.
Dataset Size

Increasing the dataset size does not lead to significant changes in performance. The highest scores are often obtained on the training dataset with only 2000 examples. This suggests that the size of the training dataset may not be the primary factor influencing performance in relation extraction tasks. Instead, other factors such as data quality, model architecture, and feature engineering may play a more significant role in determining the model's effectiveness in capturing entity relationships within documents. Therefore, focusing on optimizing these factors might yield better results in relation extraction tasks rather than solely relying on dataset size.
Prompting
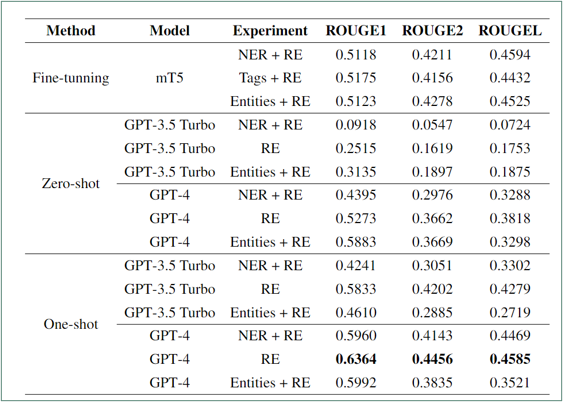
Fine-tuning the mT5 model leads to consistent performance, indicating its effectiveness in capturing entity relations in document-level tasks.
However, when it comes to GPT-3.5 Turbo and GPT-4, their performance varies across different experimental setups. This highlights the importance of careful model selection for document-level entity relation extraction tasks, as different models may excel under different conditions.
In the zero-shot experiments, GPT-4 consistently outperforms GPT-3.5 Turbo across all experiment types and even surpasses the fine-tuned T5 model. This indicates that GPT-4 has a natural ability to capture entity relationships without specific fine-tuning on the task.
In the one-shot experiments, GPT-4 demonstrates superior performance compared to GPT-3.5 Turbo. However, GPT-3.5 Turbo performs better when using the one-shot method, emphasizing the significance of providing explicit examples for this model to perform well.
Overall, the results underscore the importance of carefully selecting the appropriate model for document-level entity relation extraction tasks, considering their performance across different experimental setups and the presence or absence of fine-tuning or explicit examples.
Conclusion
This study focused on document-level entity relation extraction and presented results from experiments using different models: T5, mT5, FLAN-T5, GPT-3.5 Turbo, and GPT-4. GPT-4 outperformed other models in ROUGE scores, indicating its effectiveness. However, performance varied based on experiment setups, including NER or entity tags.
The study has some limitations. ROUGE scores measure summaries, not entity relation extraction accuracy. Generalizability to other domains and datasets needs exploration. Longer documents (beyond 512 tokens) pose challenges. Future research can address these limitations and explore new strategies, enhancing model accuracy for real-world entity relation extraction tasks.