
Multi-Task Learning with Intermediate Continual Learning for Industry NLP Use Cases
Utilizing adapters and hypernetworks to efficiently, effectively, and continuously train multiple tasks


Background and motivation
Since the introduction of the pre-train and fine-tune transfer learning paradigm introduced by Devlin et al. (2019), the approach has been preserved until now. There are now different generative methods, but they scale well with an increase in model size (Lester et al., 2021), not making them accessible to everyone. The problem with the mentioned transfer learning paradigm is that it requires fine-tuning a new large language model (LLM) for each new task, which is unsustainable in terms of time, storage, and energy.
We would like to find an efficient, yet effective multi-task learning (MTL) method which would be able to handle learning multiple tasks using less time and storage space, eventually leading to less energy consumption. All this should be achieved while preserving the performance as in single-task learning (STL). The method should be easily accessible to all small to medium-sized companies, so it should be able to run on a single or few mid-range graphics processing units (GPUs). For that reason, the method should be discriminative, while generative ones require too large LLMs, e.g. 175B parameters for GPT-3 (Brown et al., 2020) and 540B for Flan-PaLM (Chung et al., 2022). Additionally, as such companies often face distribution shifts over time and continuously-incoming requirements from their clients, the method should be liable to continual learning (CL).
In this blog, we write about finding such a method, which will be able to handle training multiple tasks jointly while also being liable to training new ones continuously. This CL does not necessarily have to be as good as lifelong learning, but only needs to cover a period of 6-12 months of new requirements. After such a period, the MTL can again be re-trained using all the previous MTL data and the newly available CL data. This method should take less time, use less storage space, be able to train on a single or few mid-range GPUs, and keep the performance at least on par with STL.
Data
Two types of tasks were examined in this work — sequence classification (CLS) and token classification, i.e. NER. Three datasets were available for the CLS task, while four were available for the NER task, resulting in a total of seven datasets. These datasets were then split into MTL and CL (data-, task-, and class-incremental), resulting in the total of 10 datasets. A multilingual version of BERT was used to to the presence of multiple languages.
Methodology
Adapters
Adapters take a completely different approach to MTL. Instead of sharing as many parameters as possible, as done in the shared encoder approach, adapters share no parameters at all, besides the pre-trained model. Alternatively, adapters train as few parameters as possible and inject them cleverly into the Transformer architecture. This makes adapters modular, less resource-intensive, and faster to train. Most importantly, performance reported for the GLUE benchmark (Wang et al., 2018) does not suffer and stays on par with STL (Houlsby et al., 2019). Two of the function-composition methods will be examined in this work — bottleneck adapter (Pfeiffer et al., 2020c) and Compacter++ (Karimi Mahabadi et al., 2021).
Pfeiffer configuration
The architecture of the bottleneck adapter will be the same as the one initially introduced in Houlsby et al. (2019), with one exception. Instead of inserting the adapter after both MHA and FF sub-layers, it will only be inserted after the latter. The reason is a two times reduction in trainable parameters, while the performance on GLUE and SuperGLUE even increases slightly (Karimi Mahabadi et al., 2021). A visual representation of an adapter is shown in Figure 1, where only the adapter after the Transformer’s FF sub-layer is used.

Compacter++ configuration
Compacter++ is inserted in the same place as the aforementioned adapter, but the parameter formulation is different. It uses parameterized hyper-complex multiplication (PHM) layers. These layers have a similar form as FC layers, with the key difference being that the weights are learned as a sum of Kronecker products. They decompose adapters into A and B matrices, where A is shared across all adapter layers, while B matrices have adapter-specific parameters. Additionally, they parameterize B as a low-rank matrix. By combining the two, low-rank parameterized hypercomplex multiplication (LPHM) layer is shown on Figure 2 and formulated here:

Adapter Fusion
Once all the adapters for the MTL part of the training have been trained, one could ask themselves if these adapters can somehow be utilized for learning an incoming CL task. The AdapterFusion (Pfeiffer et al., 2020a) approach deals with training a fusion of previously trained adapters in order to solve a single target task. It is a different approach to transfer learning. Figure 3 shows how the Adapter Fusion is inserted into each Transformer layer. Newly introduced fusion parameters learn to combine previously trained adapters as a dynamic function of the target task data. Similarly to attention (Vaswani et al., 2017), a contextual activation of each adapter is learned. Given the adapters and target task data, AdapterFusion learns a parameterized mixer of the available adapters.

Hypernetworks
Hypernetwork is a bridge between the shared encoder and adapters — it shares parameters through a hypernetwork, but also keeps and generates task-specific parameters. A simple visual overview of the hypernetwork approach is shown in Figure 4. Task embeddings are kept task-specific, while the hypernetwork, depending on the given embedding and its own parameters, generates target model parameters. In our case, a target model is the bottleneck adapter.
A hypernetwork approach that we used is from Üstün et al. (2022). The architecture is shown in Figure 4. Besides the task embedding, their work also introduces language and layer embeddings. Separating the task embeddings from language embeddings enables transfer to arbitrary task-language combinations at any time. In our experiments, language embeddings were kept the same for all the tasks, but were also be trained end-to-end. Layer embeddings were introduced in order to avoid having a different hypernetwork at each Transformer layer. This way, layer embeddings significantly reduce the number of parameters and allow for information sharing across layers. During training, only the corresponding task and language embedding were updated for each batch, depending on the task and language that the batch was sampled from. Additionally, layer embedding corresponding to the current Transformer layer is also updated. Task, language, and layer embeddings are concatenated and fed into a source projector network Ps, consisting of two FF layers and a ReLU activation. The idea of the Ps component is to reduce the size of the input embedding and potentially learn the interactions between the task, language, and layer embeddings.
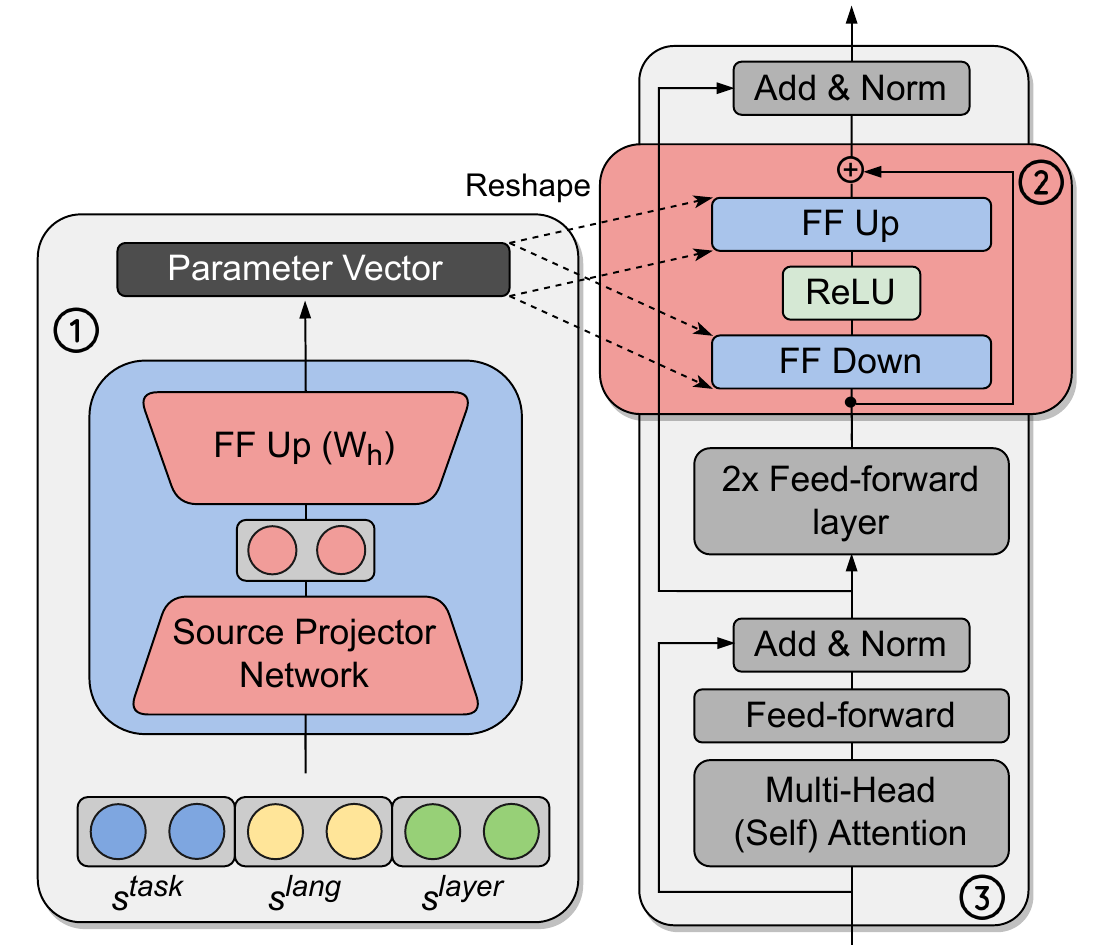
Besides the FF down- and up-projection matrices, a layer norm is also generated and trained via a hypernetwork. A slightly larger learning rate is used due to randomly initialized weights in a hypernetwork. A pre-trained encoder-based model is frozen. In order to achieve heterogeneous batches, gradients are accumulated over 4 steps before making an optimizer step. This way, a shared hypernetwork achieves gradient directions from multiple tasks before eventually following these directions. This should mitigate catastrophic interference, which is already largely mitigated by not sharing the parameters directly. Instead, a proxy, i.e. a hypernetwork, is shared. Instead of size-proportional sampling, temperature-based sampling with T=2 was used. Additionally, all CLS losses were divided by 5.0 and each point-loss by log(n), where n is the number of possible labels for the corresponding task. This was done to ensure a more stable training, regardless of the task type or number of possible labels.
When continuously training new tasks on top of the jointly trained hypernetwork model, CL regularization loss is added. This loss term is calculated using the adapter and layer normalization parameters generated by the hypernetwork, not the hypernetwork and embedding parameters directly. The reason is that the change in embedding and hypernetwork parameters is not important, as long as the parameters generated by these components do not change by much. The generated parameters are the ones being used in the model’s forward pass when the textual input is given.
There were two similar CL regularization methods examined, named type 1 and type 2 CL methods. Type 1 CL method penalized the sum of squared differences between the generated parameters before and after each optimizer step. This approach is expected to suffer in performance due to generated parameters changing slightly in each step during training. This leads to regularization loss being calculated using the generated parameters before the latest optimizer step, which could largely differ from the actually generated parameters before the beginning of training. Thus, the type 2 CL method compares the parameters generated before the start of training with the currently generated ones and calculates the loss between the two.
Results
Overview
The overview of the results is shown in Table 1. It can be seen that STL, adapters, Adapter Fusion, and hypernetwork all perform similarly within one macro average F1-score point. The hypernetwork CL performance downgrade is also shown in the table. The results shown are after two rounds of CL with three and two tasks respectively. The performance downgrade is reasonable for high-resource NER tasks, but becomes overly amplified for low-resource CLS datasets (130-475 training examples). A shared encoder approach has significantly lower results and suffers from an inability to efficiently continuously learn new tasks.

STL does not show any superiority over adapters and hypernetworks. Additionally, training it takes longer and requires more trainable parameters, as shown in Table 2. Although a compacter++ configuration is slightly more efficient than a Pfeiffer one, the results are notably different (see Table 3). Adapter Fusion, other than the fact that it does not reach the performance of ST-adapters, is also longer to train and much more parameter heavy due to the fusion of all the available adapters. Here, it should be noted that a fusion for CL CLS tasks consisted of two previously trained CLS adapters, while a fusion for CL NER tasks consisted of three NER adapters. These are small numbers, and a fusion can be made of even more adapters, which then accordingly requires longer training and inference times. A shared encoder approach does use more parameters than other non-STL methods, due to the whole encoder. Its training time is additionally the shortest, but due to the usage of 16-bit mixed precision. Hypernetwork ensures 91.38% number of trainable parameter reduction. Training time is only reduced by 15%, making adapters faster to train. This training time increases during CL, especially when there are many MTL tasks whose forgetting should be mitigated.
A longer hypernetwork CL training time due to CL regularization loss also needs to be taken into account as a downside. Generating all the possible previous adapters of all the previous tasks after each optimizer step is an expensive operation.

Adapters
A performance comparison of the Pfeiffer and compacter++ adapter configuration is shown in Table 3. Pfeiffer configuration, the one that does not further reduce the number of parameters by using LPHM layers, consistently outperforms the compacter++ configuration.

Adapter Fusion
Adapter Fusion test set performance comparison is shown in Table 4. As expected, the fusion of Pfeiffer configuration adapters also performs better or equal for all the datasets than the one of compacter++ adapters.

Conclusion
Adapters and hypernetworks proved as more efficient and equally effective approaches as STL. The adapter approach treats each MTL and CL task with a separate adapter, while hypernetwork separates MTL and CL phases. Adapters with Pfeiffer configuration reached a performance of STL. The hypernetwork forgetting rate for previously trained tasks was up to 2 macro average F1-score points, while low-resource CLS tasks with only 130-475 training examples faced losses of up to 35 percentage points. When continuously training a hypernetwork on new tasks, they mostly reached satisfactory performances, with extremely low-resource CLS tasks again struggling.
The proposed adapters approach is limiting in its similarity to STL, with a reduction of 28.4% in training time and 99.16% in trainable parameters. A separate adapter is deployed for each task. On the other hand, hypernetwork approach reduces the training time by 15% and trainable parameters by 91.38% and separates the joint MTL and CL phases. Additionally, a hypernetwork allows for some valuable knowledge sharing. However, during the CL phase, it struggles with low-resource CLS tasks trained during both MTL and CL phases.
These findings can be practically incorporated in companies serving many clients and their use cases and requirements. It allows them to train the models faster using only one or few mid-range GPUs, save the models using less storage, integrate them easier with ML systems, and continually train them, all whilst preserving an on-par performance with STL.