
Named Entity Recognition Using Question Answering in Zero- and Few-Shot Settings

The human race produces copious amounts of documents daily to aid its effective functioning. Even though digitalization allows the automatic processing of documents when they are stored in an appropriate format, this is not the case for documents that are printed or hand-written. The introduction of Large Language Models (LLMs) in conjunction with Optical Character Recognition (OCR) systems allows us to effectively extract the relevant information from these documents. However, these models are quite expensive to train from the ground up (e.g., training of GPT-4 costs about $100M). Due to this fact, the standard paradigm for using such a big and expensive model consisted of two distinct phases: pre-training and fine-tuning. The pre-training phase constitutes training the model using a self-supervised pre-training objective such as masked language modeling, sequence reshuffling, and next token prediction. During this phase, the model is presented with a large corpus (e.g., LLaMA 2 was pre-trained using ~2T tokens) from which the model gains general knowledge. The model is further specialized during the fine-tuning phase to perform a specific task such as document classification or Named Entity Extraction (NER).
In this post, we explore how the model performs when trained using as little data as possible. The idea is that the model has already seen similar examples during the pre-training and that it needs only a little bump in the right direction.
The task that we are solving is NER using Question Answering (QA) task. NER is a task in which the model has to extract the relevant (named) entities from the text. By using the QA task, we prompt the model to extract relevant entities using a natural question to which the model has to provide an answer.
Model
The model of choice for this experiment is Fine-tuned Text-to-Text Transfer Transformer (Flan-T5). Flan-T5 is a generative transformer-based model with a full encoder-decoder architecture. This means that the encoder consumes the input text and produces a latent representation which the decoder uses to generate a new sequence. Also, the model was further fine-tuned using 1.8k various tasks. We used the base variant of the model due to its timid size of 250M parameters (for reference, GPT-4 supposedly boasts 1T parameters). However, the T5 model has its drawbacks. Most notably, the model is limited to 512 input tokens.

Data
For our experiments, we used four different proprietary datasets containing invoice-type documents in German. To follow the Q paradigm of our experiments, we formatted the dataset to contain three fields: context, question, and answer. To create the context field, we split the document into pages and collected all of the words into a single string. This helped alleviate some of the issues related to the model's input token limit. Furthermore, we formed the question by asking the model about a specific entity type present in the context. Lastly, the answer field contained all of the possible answers to a given question within the context. Here is a simple example:
'context': 'Luke Skywalker destroyed the Death Star. Young Skywalker achieved this by piloting the X-wing starfighter.'
'question': 'Who is the main character in this text?'
'answer': ['Luke Skywalker', 'Young Skywalker']
Experiments
To gauge how the reduced quantity of training data affected the performance, we performed zero- and few-shot experiments. While training the model in the zero-shot setting, we introduced examples only from the non-target dataset. For instance, if DS1 was our target dataset, we trained the model using examples from DS2, DS3, or DS4.
The zero-shot experiments that we performed can be roughly divided into two groups. In the first group are the examples in which we used all three non-target datasets for training and validation. In this group, we increased the number of training examples from each non-target dataset from 100 to 400. In the second group, we included a different combination of non-target datasets in the training set. The number of examples from each of the included non-target datasets amounted to 400.
For the few-shot setting, we introduced a limited number of training examples from the target dataset. Again, we had two families of experiments. In the first part, we included 400 examples from each of the non-target datasets and increased the number of examples from the target dataset from 100 to 400. Also, in the second group of the few-shot experiments, we kept the number of examples from the target dataset fixed at 400, while trying different combinations of the included non-target datasets. In this case, we also kept the number of examples from the non-target dataset at 400. Since subsampling can produce noise, we ran all of the aforementioned experiments 10 times which were averaged to produce the final result.
Additionally, we conducted a pure zero-shot where we did not update the model's parameters to achieve the lower-bound baseline. Also, we did the full-scale fine-tuning on the whole training set of the target dataset to obtain upper-bound baseline results.
Results
Zero-shot
Increasing the number of examples from non-target datasets group
As we can observe in Figures 2-5, the initial introduction of training examples from the non-target dataset did improve performance. However, any increase in the number of training examples resulted in only a marginal improvement. Also, for the experiments with dataset DS3 as the target dataset, we note a drop in the performance. This is probably because DS3 comprised a unique set of entity types. The model probably learned to solve the task during the early stages of training but became overfitted to the seen entity types as the number of training samples increased.
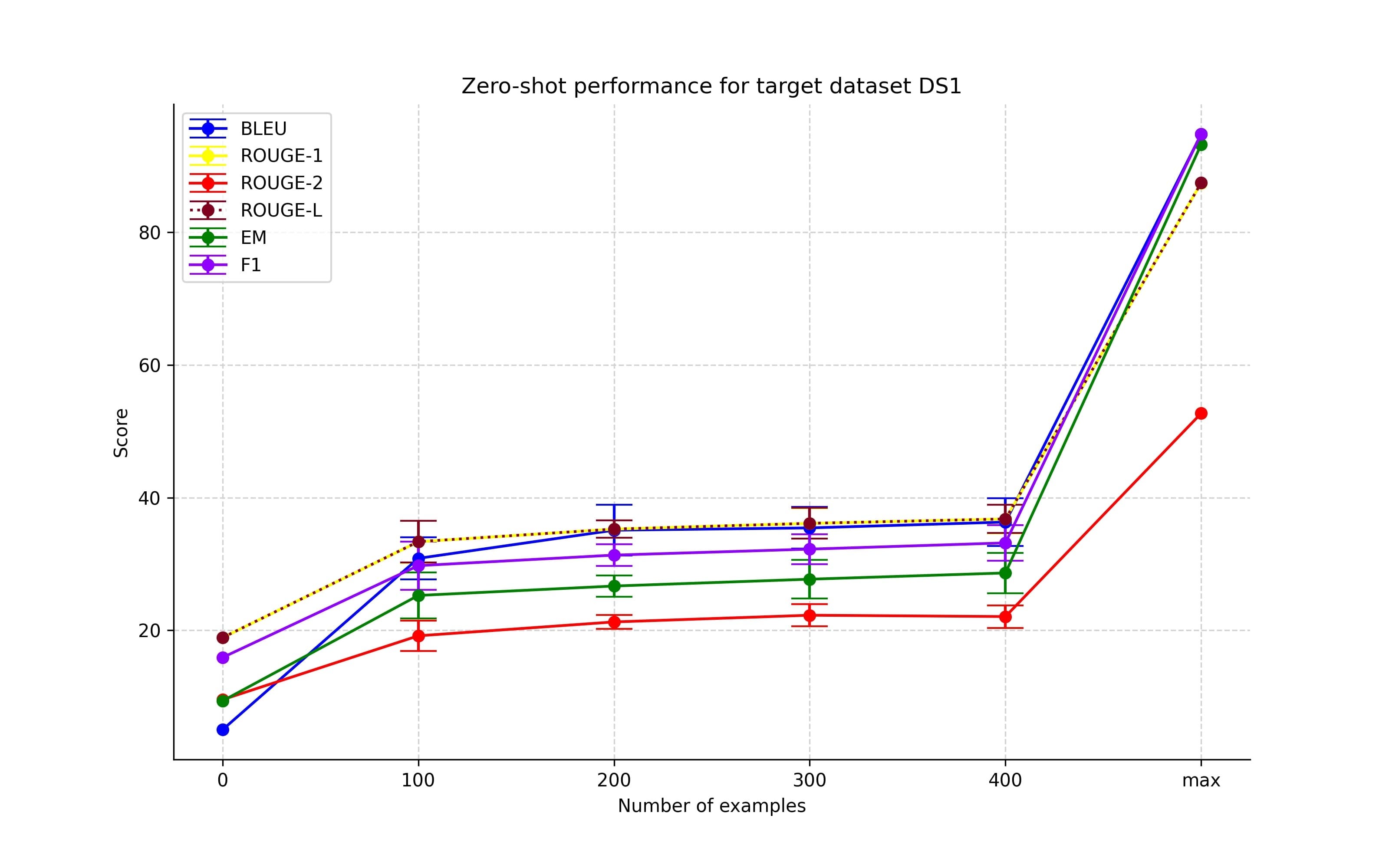

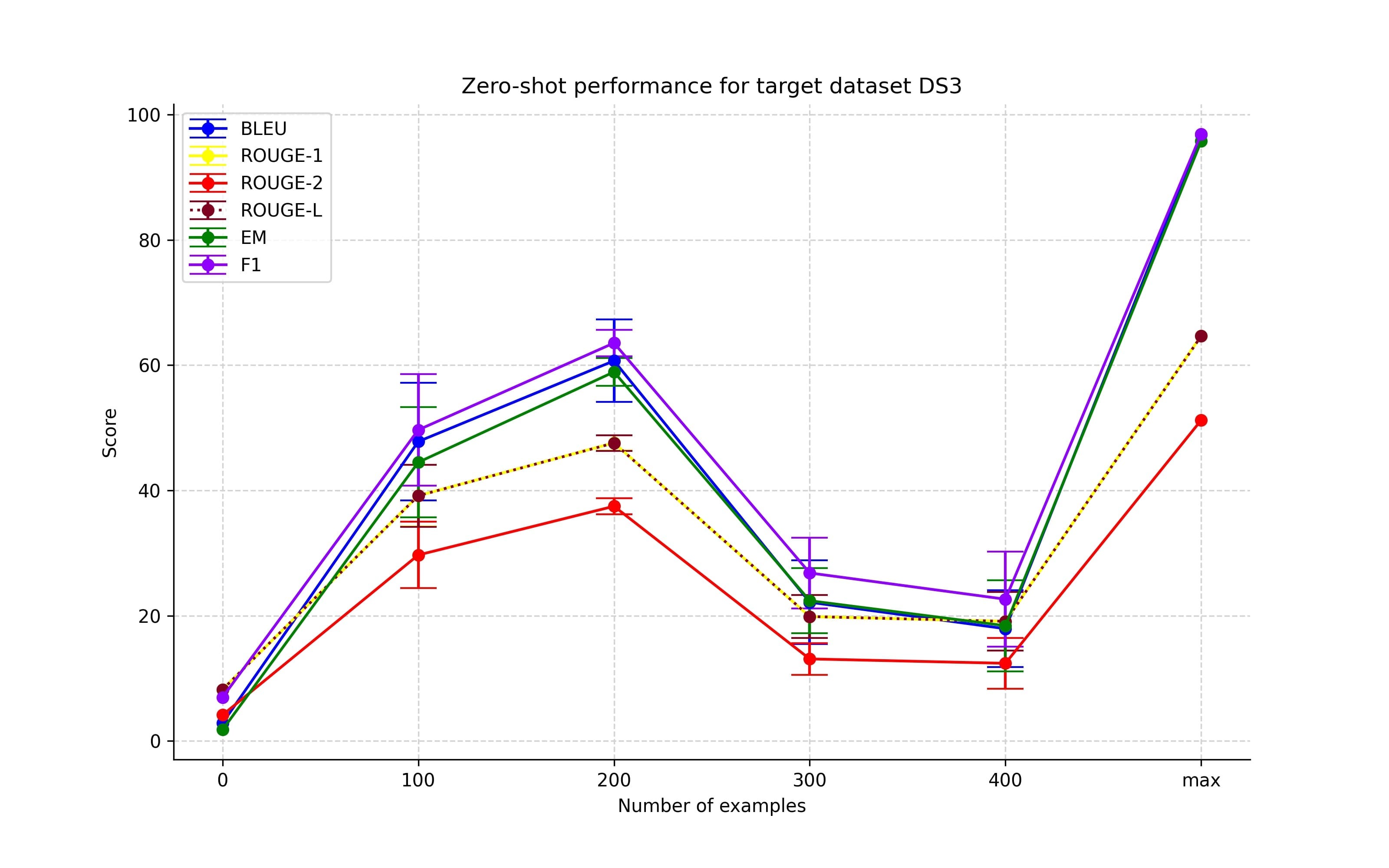
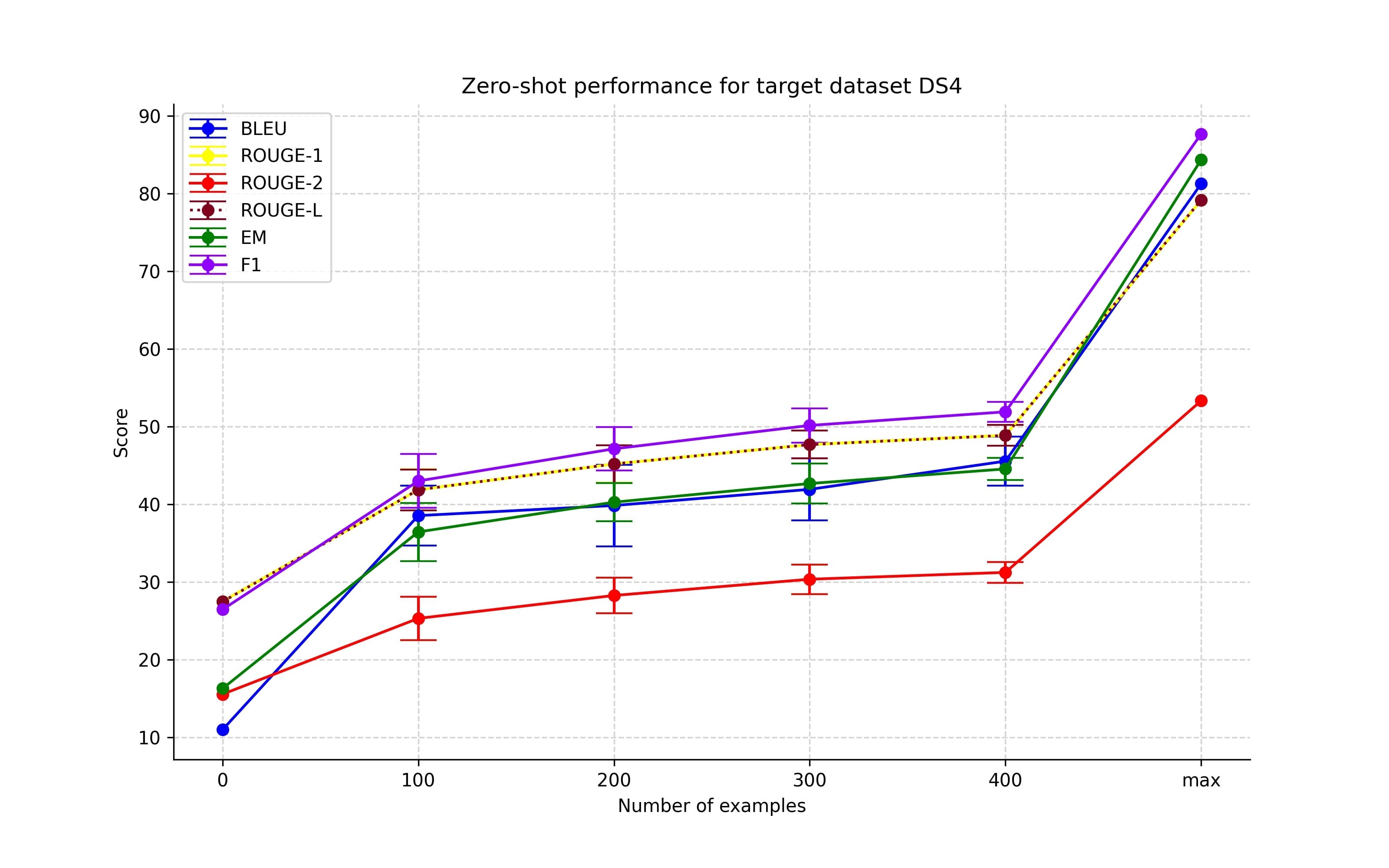
Different combinations of non-target datasets group
In experiments in which we aimed to explore how the number of included datasets impacted the performance, we did not find a link between those two. However, the results showed that the presence of certain datasets in the training set impacted the performance when tested on specific datasets. For instance, performance for target dataset DS1 proved to be higher when the model was trained using only DS4 than when DS2 or DS3 were included in the training dataset.
Few-shot
Increasing the number of examples from the target dataset group
Figures 6-9 showcase the results of the first set of few-shot experiments. These experiments show that adding more training examples from the target dataset improves performance. Even though this is an expected result and the results are not on par with the full-scale fine-tuning, this confirms the idea that including only a limited number of examples can lead the model in the right direction.

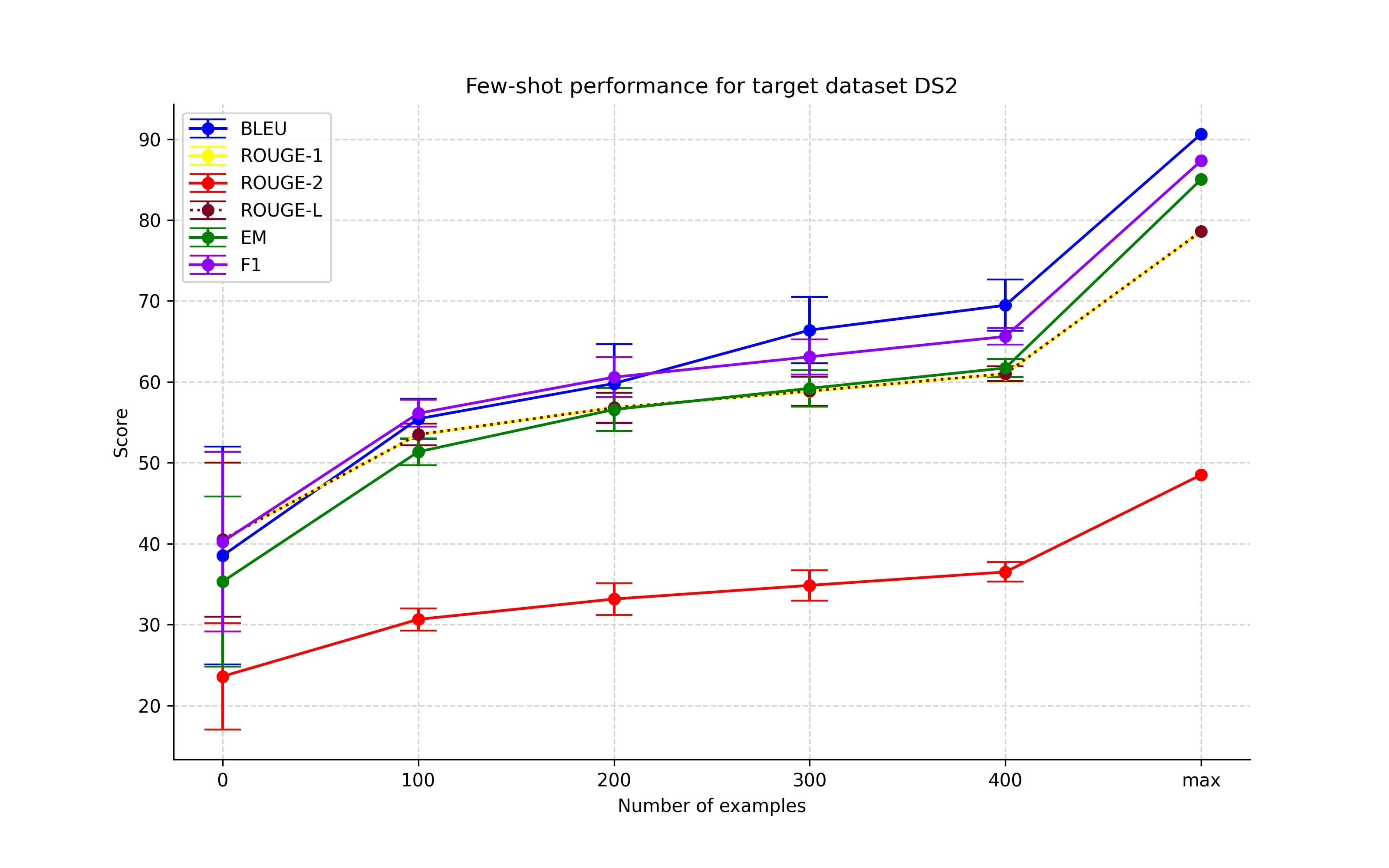
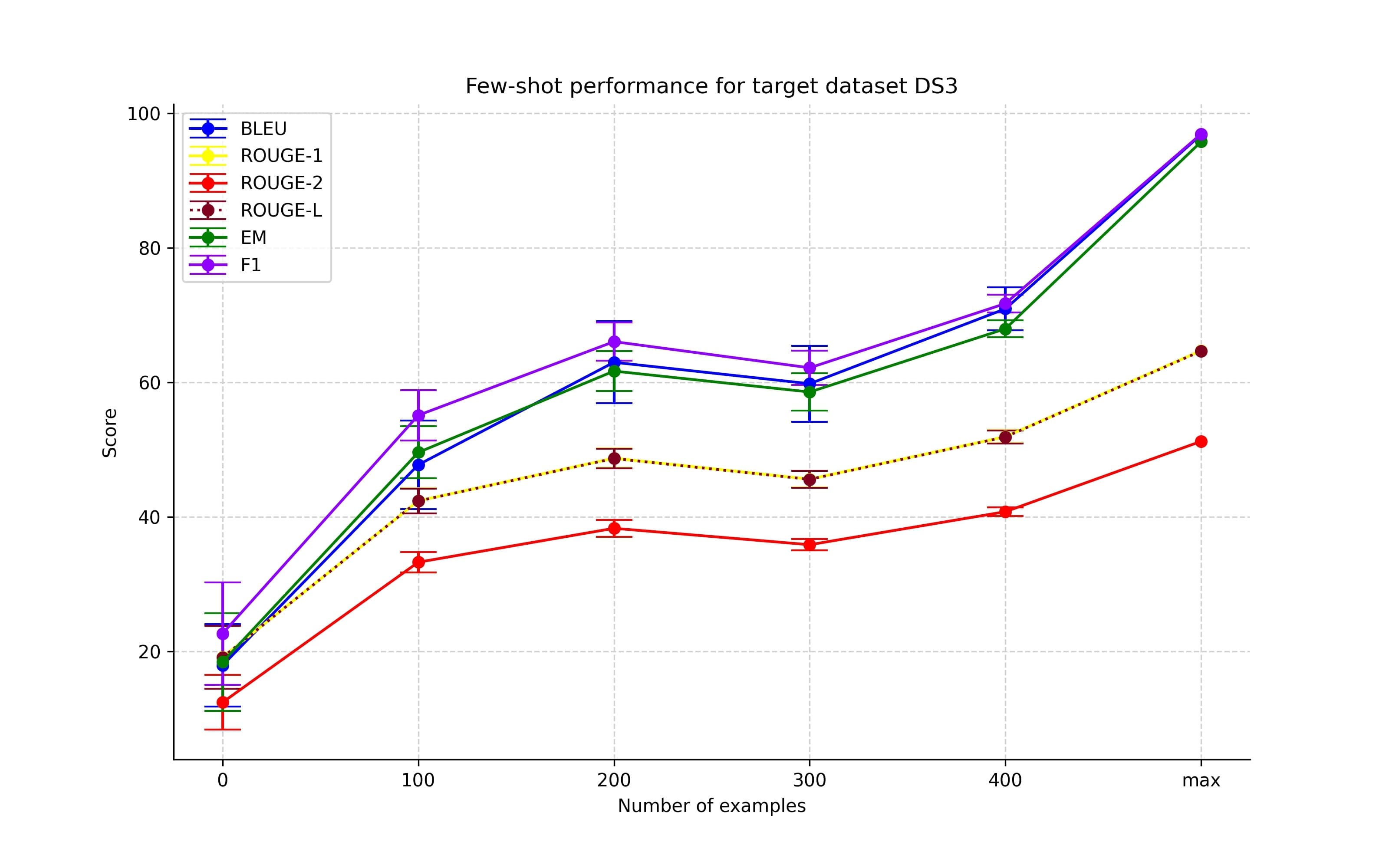
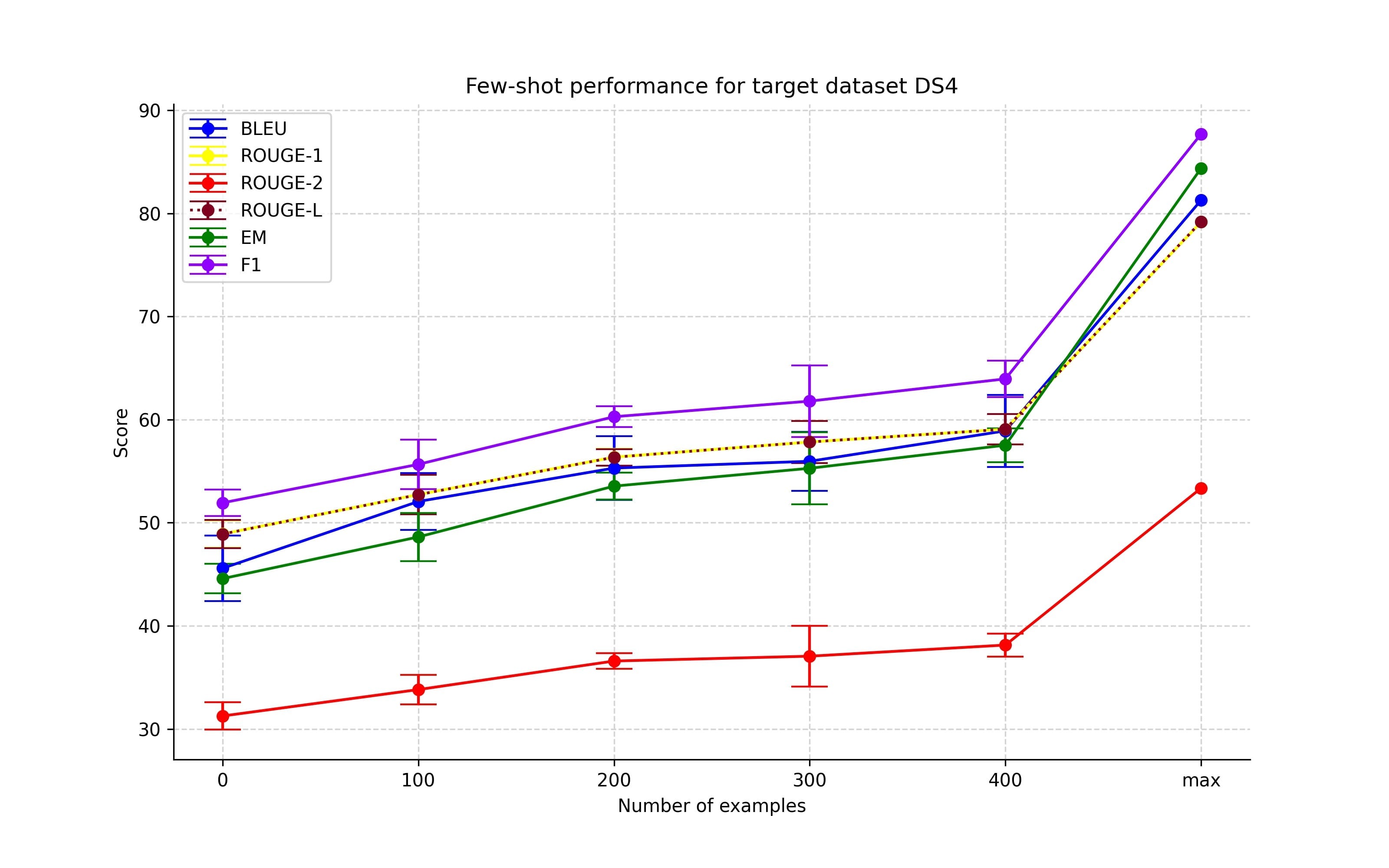
Different combinations of non-target datasets group
In the experiments where we included different numbers of datasets into the training set, we did not observe such differences in performance as we did in the zero-shot setting. However, we noted a high standard deviation in the results among the experiment runs. We attribute this to two main causes. The first one is the random sampling. It is possible that we hit a local minimum or maximum in the performance, or that the produced sample contained some difficult examples. Secondly, it is possible that there existed some ambiguity among the documents from different datasets. When the model was trained using DS2 or DS3 and tested using DS1 it yielded a high standard deviation, which is also supported by the results from the zero-shot case.
Key takeaways
The results that we obtained in this research pose a promising prospect. Even though the performance is not at the level of fine-tuning the model using the high-resource dataset, the results showcase that the few-shot setting can be a viable option for prototyping and proof of concept solutions, or when using a low-resource training dataset. Another benefit of using a reduced dataset is a reduction in training time. For example, a single run of training in the few-shot setting took about 45 minutes, while the full-scale fine-tuning took around a day. Finally, for high-performance demands, full-scale fine-tuning remains the king, but with the arrival of bigger and more advanced models, this might change.